Camillo Sðrs
Faculty of Computer Science
Helsinki University of Technology
Camillo.Sars-at-iki.fi
The IPv6 address space differs from the IPv4 address space in several ways. There are new address types and the fields of the addresses are assigned different meanings. This paper describes the IPv6 address space as laid out in several Internet RFCs and Internet Engineering Task Force Internet Drafts and also presents some methods designed for address assignment and management.
When IPv6 was in its early stages, one of the main topics of the discussion was how long the IPv6 address should be. The IPv4 address is 32-bit, with a theoretical maximum of over four billion addresses. The hierarchy of the IPv4 address, i.e. network, subnet and host, reduces the actual amount of addresses available. In [HRATIO] Huitema presents what he calls the H ratio for address assignment efficiency. It is calculated with the formula
log (number of objects)
H = -----------------------
available bits
In the following examples Huitema uses base 10 logarithms, as that is the more natural way of thinking of large numbers. Thus the H ratio ranges from 0 to 0.30102 (log10 of 2).
To try to figure out how large the IPv6 address space should be, Huitema uses some examples of similar numbering schemes. The focus is on how large the systems grew before they had to be extended to allow new nodes to be added to the system.
With these examples in mind Huitema constructs the following table for the different possible IPv6 address sizes. The numbers express the maximum number of IPv6 addresses.
| bits | Pessimistic (0.14) | Optimistic (0.26) |
|---|---|---|
| 32 | 3*104 (!) | 2*108 |
| 64 | 9*108 | 4*1016 |
| 80 | 1.6*1011 | 2.6*1027 |
| 128 | 8*1017 | 2*1033 |
An estimate for the number of Internet hosts in the future is 1015. The 64 bit alternative lies below or above the estimate depending on your point of view. The 128 bit address, however, is more than enough. As a matter of fact, if you assign 80 bits of the address to the "network" part and leave 48 bits (the IEEE hardware link layer address length) for stateless address autoconfiguration, you still end up with a reasonable worst case of almost 1012.
The IPv6 addresses are 128 bits long.
An IPv6 address consists of 128 bits, and is usually written as a text string of eight 16-bit hexadecimal numbers. The address itself refers to an interface, rather than a node as in IPv4, and one interface may be assigned several addresses.
Addresses will usually have long strings of zero bits, so a textual
format for compressing zeroes in the address has been devised. One
and only one string of consecutive zeros may be replaced by
'::'. [ADARCH]
| Address | Abbreviation | Description |
|---|---|---|
1080:0:0:0:8:800:200C:417A
| 1080::8:800:200C:417A
| a unicast address |
FF01:0:0:0:0:0:0:43
| FF01::43
| a multicast address |
0:0:0:0:0:0:0:1
| ::1
| the loopback address |
0:0:0:0:0:0:0:0
| ::
| the unspecified addresses |
During the transition period from IPv4 to IPv6, both types of
addresses will coexist on the Internet. IPv4 type addresses in the
IPv6 environment may be written as x:x:x:x:x:x:d.d.d.d.
In this representation, the IPv4 address is d.d.d.d and
its IPv6 prefix is x:x:x:x:x:x.
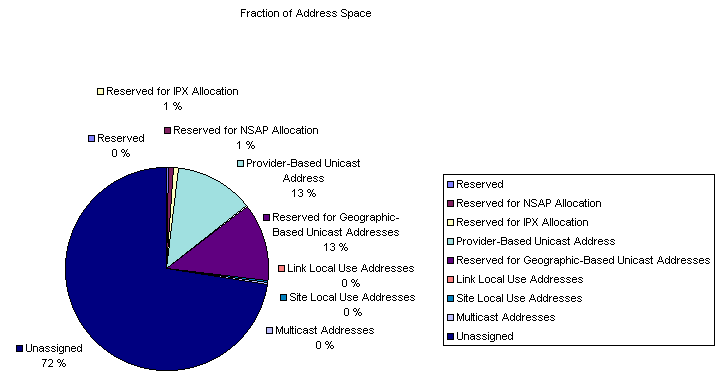
According to [ADARCH] the IPv6 address space will be divided into parts as shown in the following table. 15% of the address space is allocated, the remaining 85% are reserved for future use.
| Allocation | Prefix (binary) | Fraction of Address Space |
|---|---|---|
| Reserved | 0000 0000 | 1/256 |
| Unassigned | 0000 0001 | 1/256 |
| Reserved for NSAP Allocation | 0000 001 | 1/128 |
| Reserved for IPX Allocation | 0000 010 | 1/128 |
| Unassigned | 0000 011 | 1/128 |
| Unassigned | 0000 1 | 1/32 |
| Unassigned | 0001 | 1/16 |
| Unassigned | 001 | 1/8 |
| Provider-Based Unicast Address | 010 | 1/8 |
| Unassigned | 011 | 1/8 |
| Reserved for Geographic-Based Unicast Addresses | 100 | 1/8 |
| Unassigned | 101 | 1/8 |
| Unassigned | 110 | 1/8 |
| Unassigned | 1110 | 1/16 |
| Unassigned | 1111 0 | 1/32 |
| Unassigned | 1111 10 | 1/64 |
| Unassigned | 1111 110 | 1/128 |
| Unassigned | 1111 1110 0 | 1/512 |
| Link Local Use Addresses | 1111 1110 10 | 1/1024 |
| Site Local Use Addresses | 1111 1110 11 | 1/1024 |
| Multicast Addresses | 1111 1111 | 1/256 |
Depending on what role an IPv6 node plays in the network, it may have much or little knowlege of the internal structure of the IPv6 address. A host may consider the address to be a contiguous string of 128 bits.
| 128 bits |
| node address |
Usually a host will know the link prefix(es) for its link(s) and that part of the address is the interface ID.
| n bits | 128-n bits |
| subnet prefix | interface ID |
Hosts on IEEE 802 LANs will probably use an address format similar to this
| n bits | 80-n bits | 48 bits |
| subscriber prefix | subnet ID | interface ID |
In some cases the network organization that a host belongs to has further partitioned the above subscriber prefix (see Topology).
| s bits | n bits | m bits | 128-s-n-m bits |
| subscriber prefix | area ID | subnet ID | interface ID |
The address 0:0:0:0:0:0:0:0 is known as the unspecified
address. It is used to indicate that the address is unknown and must
therefore never be assigned to any node. It is used as source address
during autoconfiguration to indicate
that the host does not know its address. The unspecified address must
not be used as a destination address.
The address 0:0:0:0:0:0:0:1 is the loopback address which
is used by a node to send packets to itself. The address must not be
assigned to any node and must not be sent outside a single node.
There are two kinds of embedded IPv4 addresses. The "IPv4-compatible IPv6 addresses" are used to tunnel IPv6 packets over IPv4 routers.
| 80 bits | 16 bits | 32 bits |
0000...0000
| 0000
| IPv4 address |
"IPv4-mapped IPv6 addresses" are addresses of nodes that do not support IPv6.
| 80 bits | 16 bits | 32 bits |
0000...0000
| FFFF
| IPv4 address |
The format of provider based unicast addresses is
| 3 | n bits | m bits | o bits | 125-n-m-o bits |
010
| registry ID | provider ID | subscriber ID | intra-subscriber |
The provider based address format is designed to allow flexible assignment of addresses in a way that makes routing cheap but still allows a multitude of different configurations. [UUALL]
There are two kinds of addresses for local use. The link-local address is used in address autoconfiguration and neighbour discovery (see Autoconfiguration). Routers must not forward packets with link-local source addresses.
| 10 bits | n | 118-n bits |
1111111010
| 0000...0000
| interface ID |
Site-local addresses can be used in networks that are not connected to the Internet. If they at some point decide to join the Internet, the site-local prefix must be replaced with a subscriber prefix. Packets with site-local addresses must not be routed outside the site.
| 10 bits | n | m | 118-n bits |
1111111011
| 0000...0000
| subnet ID | interface ID |
Anycast addresses are allocated from the unicast range and are syntactically indistinguishable from unicast addresses (see Anycast).
The IPv6 anycast addresses are taken from any of the unicast address ranges. They differ in the fact that the same address is assigned to several interfaces, which must know that the addresses are anycast addresses. A node sending to an anycast address does not need to know that it is an anycast address.
A packet sent to an anycast address is routed to the "nearest" node that has that address; the measure of distance depends on the routing protocol used. There is little experience of the use of anycast addresses in an internet, and it is expected that the use will mostly be site-local. Routers will respond to several different anycast addresses and in that way support different routing policies.
Currently two restrictions are imposed on IPv6 anycast addresses. [ADARCH]
| n bits | 128-n bits |
| subnet prefix |
0000...0000
|
The IPv4 broadcast address concept has been replaced by multicast addresses. A multicast address identifies a group of nodes, and a node can belong to any number of multicast groups.
| 8 | 4 | 4 | 112 bits |
11111111
| flgs | scop | group ID |
The first octet is FF (11111111) which is
the multicast address prefix. The second octet identifies the type of
multicast address, divided into flags (flgs) and scope (scop).
| 0 | reserved |
| 1 | node-local scope |
| 2 | link-local scope |
| 5 | site-local scope |
| 8 | organization-local scope |
| E | global scope |
| F | reserved |
Permanent multicast addresses have the same meaning in every scope,
e.g. the group id 43h might be assigned to the "NTP
servers group". This means that FF02::43 identifies all
NTP servers on the same link as the sender, whereas
FF0E::43 identifies all NTP servers on the Internet. It
is evident that multicast addresses of a local scope should be
preferred to global multicast addresses.
Transient multicast addresses have meaning only within a particular
scope, so two different sites can use the same address for different
purposes. The permanent multicast address with the same group ID as a
transient address also has no relationship to the transient
group. I.e. FF02::43 is distinct from
FF12::43.
Multicast addresses must not be used as source addresses or appear in any routing headers. Using multicast addresses in this context would make error recovery impossible.
The multicast addresses with the group ID of zero, i.e. FF00:: -
FF0F::, are reserved and will never be assigned to any
multicast group. In addition to these, the following groups are
pre-defined. [ADARCH]
FF01::1 all node-local nodes
FF02::1 all link-local nodes
FF01::2 all node-local routers
FF02::2 all link-local routers
FF02::C all link-local IPv6 DHCP servers and relay agents
The neighbour discovery protocol uses solicited-node multicast
addresses. They are of the form FF02::1:XXXX:XXXX, where
XXXX:XXXX is the lower 32 bits of the address. Selecting
the solicited-node address this way often reduces the amount of
multicast groups a node must join, as most of its uni- or anycast
addresses differ only in their prefixes. This is important as a node
must listen to the associated solicited-node addresses for every uni-
and anycast address it has.
[ADARCH] requires that every host recognize the following addresses as referring to itself:
In addition to these, a router must recognize the following addresses as identifying itself:
Street addresses have a clear topology. Everyone who ever has sent a letter has some kind of idea of how the letter is transported from A to B. For example, a letter from Oklahoma, USA to the (imaginary) address of
Mr John Smith
Mannerheimintie 345 A 67
FIN - 00300 HELSINKI
FINLAND
may be transported from the local post office to the Oklahoma central office from where it is flown to Europe, perhaps even straight to Finland. It would then be put with the mail going to Helsinki, and in Helsinki sent to the office of district 00300. Only there would the first two rows be significant; if there was no such address, or Mr Smith never lived there, the letter would be returned, else it would be delivered.
The designers of IPv6 have recognized the need to create topological addresses to make routing easier. The address space is so large that uncontrolled assignment of addresses soon would cause the routing tables to grow too big. [UAALL] presents an architecture for allocating IPv6 unicast addresses in a topologically reasonable manner. Even though the assignment of addresses is partly a policy matter, partly a question of routing, we briefly present the high level division of the addresses proposed.
The object of the unicast address assignment scheme is to create a hierarchy that greatly reduces the work needed to route packets over the Internet. This is achieved by allocating all addresses within a domain so that they have a common prefix. When two domains want to exchange routing information, they only need to pass the domain prefixes to each other. The routers can then be configured to route any packets with those prefixes to the other domain.
The Internet is expected to grow so large that even the "domain" of routing domains will grow too large to handle with a flat address model. It is therefore recommended that domains that are "close" in the physical topology of the Internet are given domain prefixes that themselves have a common prefix. How large the different parts of the prefixes need to be is dictated by the topology and size of the domains, and may vary in different parts of the Internet.
It is recommended that organizational and administrational boundaries should be ignored when assigning domain prefixes. Often the network topology does not reflect these boundaries, which means that assigning addresses according to them would lead to inefficient routing.
In the case of country boundaries the network connectivity seems to follow the country borders quite well. This should be reflected in the assignment of prefixes, but care should be taken as there may well be exceptions from this rule.
The stateless address autoconfiguration process is described in [ADCONF] and is closely related to the Neigbour Discovery protocol. The aim of stateless autoconfiguration is to make connecting machines to the network as easy as possible. In many cases it actually allows you to plug your machine into the network and start using it right away.
For autoconfiguration to work, an interface must be able to provide a unique identifier such as its link-layer address; in IEEE 802 networks the network address will be used. This identifier is then used to create a link-local IP address and all necessary multicast addresses for the node.
The tentative link-local IP address is announced in a Neighbour Solicitation message, which is repeated several times. If no Neighbour Advertisement message is received in response, the address is assigned to the interface. This does not actually verify that the address is unique, as the link may have been broken at the time of the Neighbour Solicitation. Later the Duplicate Address Detection protocol may be used if there is a suspicion that the address is not unique. Before the tentative address is assigned to the interface, the node may only send and receive Neighbour Solicitation and Advertisement messages.
The stateless autoconfiguration protocol is powerful enough to work in large networks with several routers, but larger sites may choose to use the stateful protocol to have more control over how the addresses are assigned. The stateful protocol is described in [DHCPv6] and is beyond the scope of this document.
Autoconfiguration also makes automatic renumbering of the nodes possible. Address prefixes and even addresses themselves have lifetimes that can be used to gracefully fade out old addresses and start using new ones instead. An address that is about to expire first becomes deprecated, which means that no new connections should be established using it, but that it still can be used on existing connections. Once an address expires, it must not be used at all.
The Neighbour Discovery protocol is used to discover local nodes, routers, link-layer addresses and to maintain reachability information based on them. It is described in [NDIP] in a form that assumes the link is broadcast capable. Links that do not support broadcast (e.g. as ATM) will have to extend the protocol to suit their needs.
The following functions are part of the Neighbour Discovery protocol.
To achieve its goals, the Neighbour Descovery protocol defines five packets. These are
The Neighbour Discovery protocol also includes support for a few
additional functions:
Inbound load on a node with several interfaces can be balanced by
responding to solicitations with different link-layer addresses.
Anycast addresses can cause several responses to one solicitation, but
the responses do not have the Override flag set. This allows the node
to choose which of the link-layer addresses it will use.
Proxy nodes may respond with advertisements for nodes not present on
the link, but that can be reached through the proxy. These
advertisements do not have the override bit set, so if the actual node
is present, it takes precedence. This is useful in mobility
management.
[NDIP] describes the following conceptual model of a host. An implementation can, and probably will, differ from this model, but must perform the same functions.
| INCOMPLETE | Address resolution in progress. |
| REACHABLE | Has been reachable recently (in tens of seconds) |
| STALE | Not known to be reachable, but no attempt to determine its reachability should be made until traffic is sent to it. |
| DELAY | Give upper layer protocols some time to determine reachability before starting a probe. |
| PROBE | Unicast Neighbour Solicitation probes are being sent. |
The Destination Cache is consulted, and if the address is not in it, a longest match is done on the Prefix list to determine if the address is link-local. Either way, the next-hop IP address is found, which is either link-local or the address of a router. The Destination Cache contains next-hop information to decrease the amount of next-hop determinations; even if next-hop determination is performed again, the cache entry does not need to be purged, as it can contain other link-layer parameters as well.
The Neighbour Cache is used to find the link-layer address of the destination. If the address is not in the cache Address Resolution is initiated in the INCOMPLETE state and the packet is queued for transmission when the address is resolved. The cache lookup may also result in Unicast Neighbour Solicitation, if the node has not been reachable lately.
When the destination is known to be REACHABLE, the packet can be transmitted.
Multicast addresses are always considered to be link-local, and a separate address resolution algorithm for each link type is required to find the link-local broadcast address to use.
The variables are set to the union of the values received in Router Advertisements. Variables that have only one possible setting are set according to the most recent advertisement. If an advertisement has some values set to "unspecified", the value of the variable must not be changed.
Router Solicitations can be sent when a node attaches to the link. The periodic Router Advertisements may be incomplete, but the response sent to a Router Solicitation is always compete. Before sending the first Router Solicitation, the node should delay for a short random time to avoid race conditions when several nodes are attached to the link simultaneously, for example after a power failure. If no response is received to the Router Solicitations, the node assumes that no routers are present, but will still listen for Router Advertisements in case a router appears on the network.
Address resolution is used to determine the link-layer address of a node whose IP address is on-link. The Neighbour Cache entry is set to INCOMPLETE and a Neighbour Solicitation message is sent to the solicited-node multicast address corresponding to the target IP address. The source link-layer address is sent with the Neighbour Solicitation, so that the response can be sent as unicast. Neighbour Solicitations are retransmitted until a response is received or the maximum limit is reached, which means that the address is unreachable.
When the solicited node receives a Neighbour Solicitation message, the Neighbour Cache entry for the sender is updated and set to the STALE state. This indicates that at least one-way transmission works, but that the return path is still untested. A Neighbour Advertisement with the Solicited flag set is then sent to the soliciting node.
Upon receipt of the Neighbour Advertisement with the Solicited bit set, the soliciting node sets its Neighbour Cache entry to REACHABLE. If the Solicited bit is not set, the message is not a response to the Neighbour Solicitation, and the entry is set to the STALE state.
The node that sent the Neighbour Solicitation knows that the path works both ways, whereas the solicited node only knows that it can receive messages. The solicited node can get knowledge of the return path from upper level protocols, or if that is not possible, by running the Neighbour Unreachability Detection algorithm.
These are the protocol constants used by a host (may wary depending on link type) [NDIP]
| Max. Solicitation Retry Delay | 1 second |
| Solicitation Retry Interval | 4 seconds |
| Max. Solicitation Retries | 3 transmissions |
| Max. Multicast Solicitations | 3 transmissions |
| Max. Unicast Solicitations | 3 transmissions |
| Max. Anycast Delay | 1 second |
| Max. Neighbour Advertisements | 3 transmissions |
| Reachable Time | 30,000 milliseconds |
| Retransmit Timer | 1,000 milliseconds |
| First Probe Delay | 5 seconds |
| Min. Random Factor | 0.5 |
| Max. Random Factor | 1.5 |
The IPv6 address assignment gives a host several addresses that it responds to. (see Required Addresses) Some hosts may need even more addresses, having several interfaces on different links. Sofar not much research has been done in this field, but several problems exist. Multihomed hosts must determine which interface to use for a transmission, much like routers do. This concept is carried even further in [MANYAD].
Bellovin proposes that IP addresses could be assigned to logical interfaces, so that a node would provide different services at different addresses. A public FTP service could have a well-known name and address, whereas a private service at the same host would use a different address. An even better example is the Archie service, which can be used remotely with an archie client or locally from a telnet prompt. The two services would have different names and addresses, thus eliminating the need to telnet to a certain port.
The ability to use different addresses for different services on the same host also has security implications. Currently a firewall needs to be able to block access to forbidden ports, and to allow connections to public ports. If the two were separate addresses, the only screening needed would be address based which is much more efficient.
It is even conceivable that every user on a host would be assigned an address of his own. This would increase the load on the host, but could provide many useful services. If an address would belong to a user, it could be used for accounting purposes, such as pay-by-use. User-level encryption would also be provided by the same mechanisms that provide host-level encryption without the need for another protocol.
The IPv6 address space along with the new any- and multicast addressing modes make the IPv6 Internet much more flexible than the old Internet. The protocol stack will be more complex, requiring a bit more processing power, but that is more than compensated for by the new features.
Configuring a host for the Internet has never been easy, so the autoconfiguration protocols are a welcome addition. Computer users are growing accustomed to "Plug-and-Play" devices and will appreciate that connecting to the Internet is equally easy. Network maintainers will find that their workload decreases markedly, as the number of misconfigured hosts drops drastically.
The Neighbour Discovery process along with Duplicate Address Detection and Unreachability Detection will probably make the new Internet more robust. Nodes react rapidly to changes in the network architecture and do not need to be reconfigured manually. Even larger renumbering operations that often are very error prone may be performed almost automatically and with better chances of success.
0-201-63395-7.
0-13-241936-X.
| Domain | A region with a common prefix, used in routing |
|---|---|
| Host | A computer on a network |
| Interface | Hardware connecting a host to a network |
| Internetwork | Several interconnected networks |
| IP address | A 128 bit number identifying one or several interfaces |
| Link layer | The low-level transmission media of a network |
| MTU | Maximum transmission unit, the largest packet that can be transmitted in one piece |
| Network | A group of computers connected to each other on some link |
| Node | Host or router |
| Prefix | Some number of the high-order bits of an address, usually written as NNNN/Y where NNNN is the prefix and Y is the number of bits |
| Router | Node providing the connection between two networks |
| Subnet | A logical part of a network with the same subnet prefix (netmask) |